Building Reasoning Mode Selection for A.X K1
At KRAFTON, we developed a technique for the A.X K1 model under the Sovereign AI Foundation Model Project that enables a single model to operate in either a fast response (non-thinking) mode or a deep reasoning (thinking) mode depending on the user’s request. In this post, we share the methods we explored from both data and model perspectives, along with the key findings from the process.
Why an LLM Needs Both Non-Thinking and Thinking Modes
We ask language models a wide variety of questions.
“Write a reply email for me” “Summarize this notice”
Some requests are simple and straightforward, while others demand multi-step reasoning:
“Solve last year’s Olympiad problem” “My code has this bug — how do I fix it?”
For simple tasks like replying to an email, a fast response leads to a better user experience. From the service provider’s perspective, it is also beneficial to use fewer compute resources on simple questions. We call this mode — where the model answers quickly with just the final answer — the non-thinking mode.
On the other hand, when users ask about an unsolved math problem or want to debug code, they prefer a thorough answer even if it takes more time. A mode that plans, reasons through multiple steps, and self-corrects is what we call the thinking mode. Thinking mode takes relatively longer to produce an answer, but it can solve incredibly difficult and complex problems.
Our goal is to incorporate both reasoning modes into a single model, so that it responds quickly and effectively to diverse questions. When a user selects a reasoning mode, it is crucial that the model operates precisely in that mode.
Why train both modes into a single model?
An alternative approach is to train separate non-thinking and thinking models and use different models for different questions. In fact, many systems adopt this approach.
Our reasons for training both modes into a single model are as follows:
- When switching modes during a conversation, it is more efficient and natural for the same model to continue the dialogue.
- Training on one mode can transfer benefits to the other mode. Therefore, we can expect a stronger final model compared to separating data and training.
- (Though not covered in detail here) It is also advantageous for continuously adjusting reasoning effort on a sliding scale, such as how long to think.
The First Step in Mode Distinction: Chat Template Design
To tell the model which mode to respond in — non-thinking or thinking — we need to design a chat template. A chat template defines how conversation messages are converted into a single long string that serves as the model’s input.
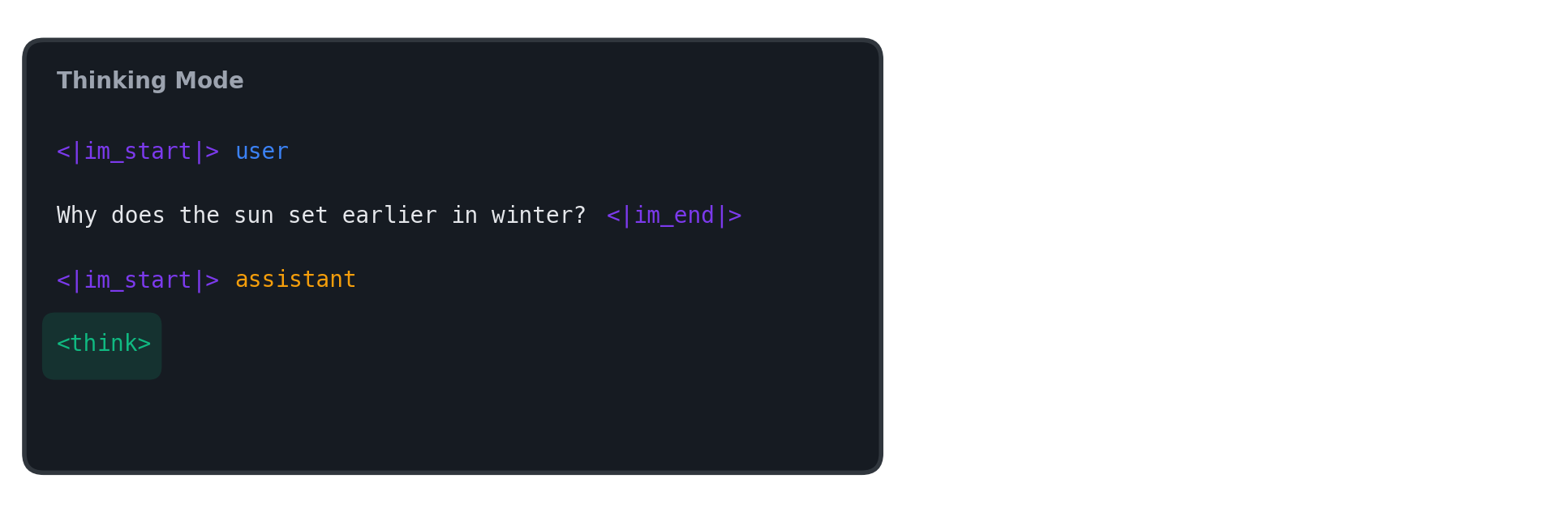
Suppose we start a new conversation with a language model. If the user asks, “Why does the sun set earlier in winter?”, the string the model sees after applying the chat template looks like this:

In this post, we assume that when thinking mode is selected, the model outputs intermediate reasoning inside a <think>...</think> block before the final answer. Therefore, in thinking mode, we append the <think> token at the chat template stage to prompt the model to immediately begin reasoning.
Next, let’s consider non-thinking mode. The simplest approach is to append an empty <think></think> block, as shown below.

However, with this approach, both modes share an identical input up to the <think> token. This means that even when thinking mode’s chat template is applied, from the model’s perspective it cannot distinguish whether it is in thinking mode or in non-thinking mode where </think> simply hasn’t been appended yet. As a result, a problem can arise where the model immediately generates </think> without any intermediate reasoning, even when thinking mode was intended.
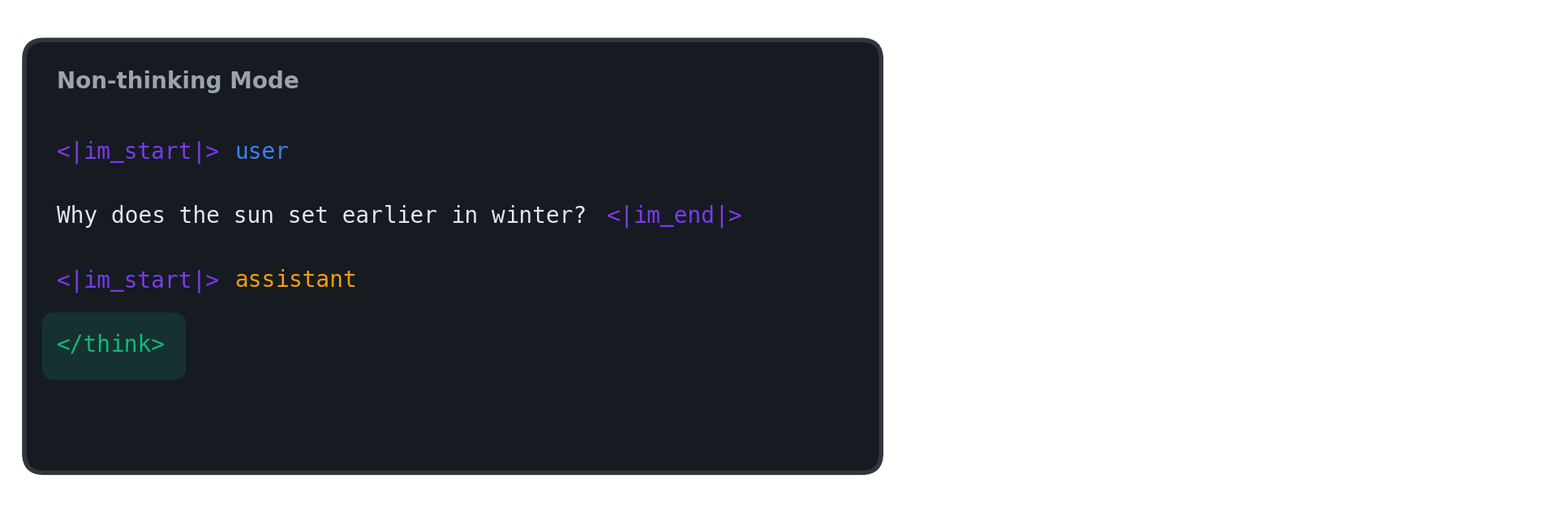
In our experiments, we addressed this by configuring the chat template to append only <think> for thinking mode and only </think> for non-thinking mode after the assistant turn.
When Modes Collapse: Getting Two Modes into One Model
Using the chat template, we clearly distinguished thinking and non-thinking modes. In thinking mode, <think> is appended after the assistant turn as a signal saying “start reasoning now,” while in non-thinking mode, </think> is appended as a signal saying “just give the answer without reasoning.” In other words, the input signals for mode selection are in place.
However, problems emerge once we enter the actual training phase. Simply mixing the two modes’ data and training leads to a phenomenon where the model starts ignoring the signals and operates in only one mode. We call this phenomenon mode collapse.
Ultimately, the success of reasoning mode selection requires satisfying two conditions simultaneously: (1) high answer quality and (2) strict format adherence. In this section, we try previously used approaches and share the results.
Experimental setup summary
- Model: Qwen3-4B-Base
- Domain: instruction-following
- Evaluation
- IFEval score (↑): instruction-following performance metric
- Format error rate (↓): rate of violating the expected format (think tags, etc.) for the given mode
- e.g., for thinking mode, the proportion of samples that fail to produce the
<think>...</think>format
- e.g., for thinking mode, the proportion of samples that fail to produce the
- Dataset
- Thinking data 46k (for thinking mode)
- [request] +
<think>[intermediate reasoning]</think>[answer]
- [request] +
- Non-thinking data 37k (for non-thinking mode)
- [request] +
</think>[answer]
- [request] +
- Thinking data 46k (for thinking mode)
Baseline: Simply Combining Both Datasets
The simplest approach is to combine both modes’ data as-is (Combined) and train. However, as mentioned earlier, the experimental results showed that format errors in thinking mode skyrocketed, and mode collapse occurred. In other words, the model ignored the <think> signal and operated only in non-thinking mode.
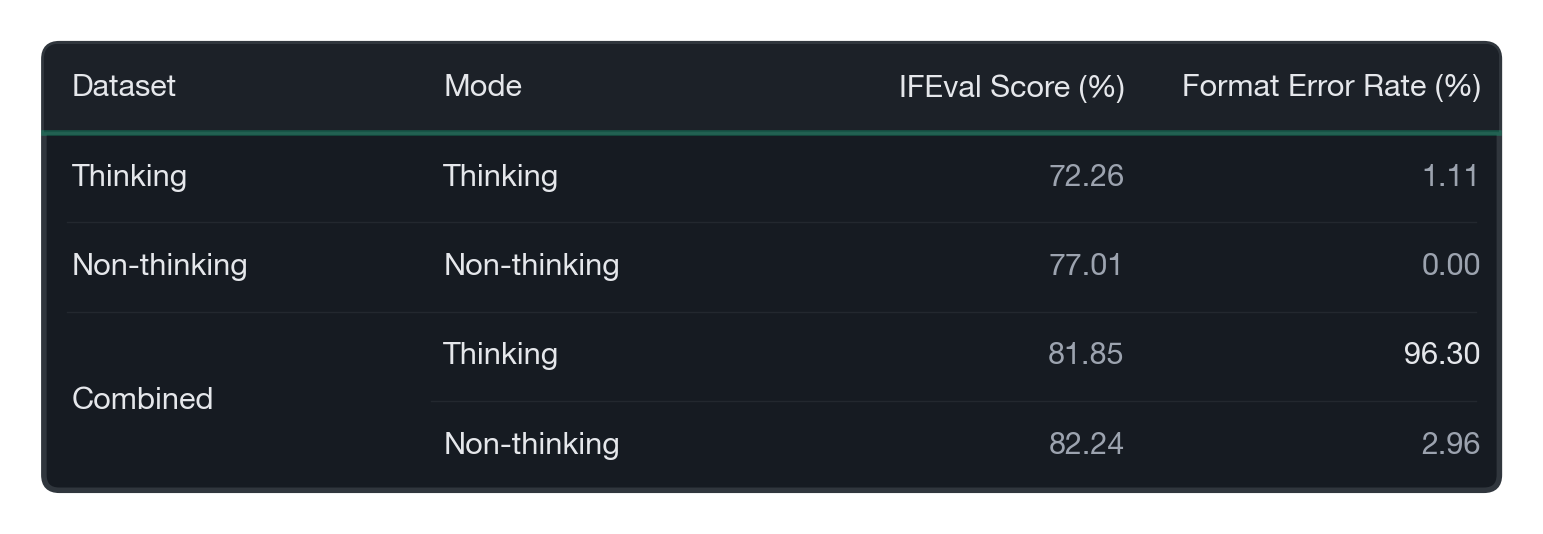
Approach 1: Adjusting the Data Ratio
The first approach we tried was training with mixed data from both modes while precisely adjusting the ratio to prevent one side from becoming overwhelmingly dominant. In EXAONE 4.0’s post-training process, a similar idea of adjusting the token ratio of thinking to non-thinking data at 1.5:1 appears, so we investigated whether such ratio adjustment could solve mode collapse.
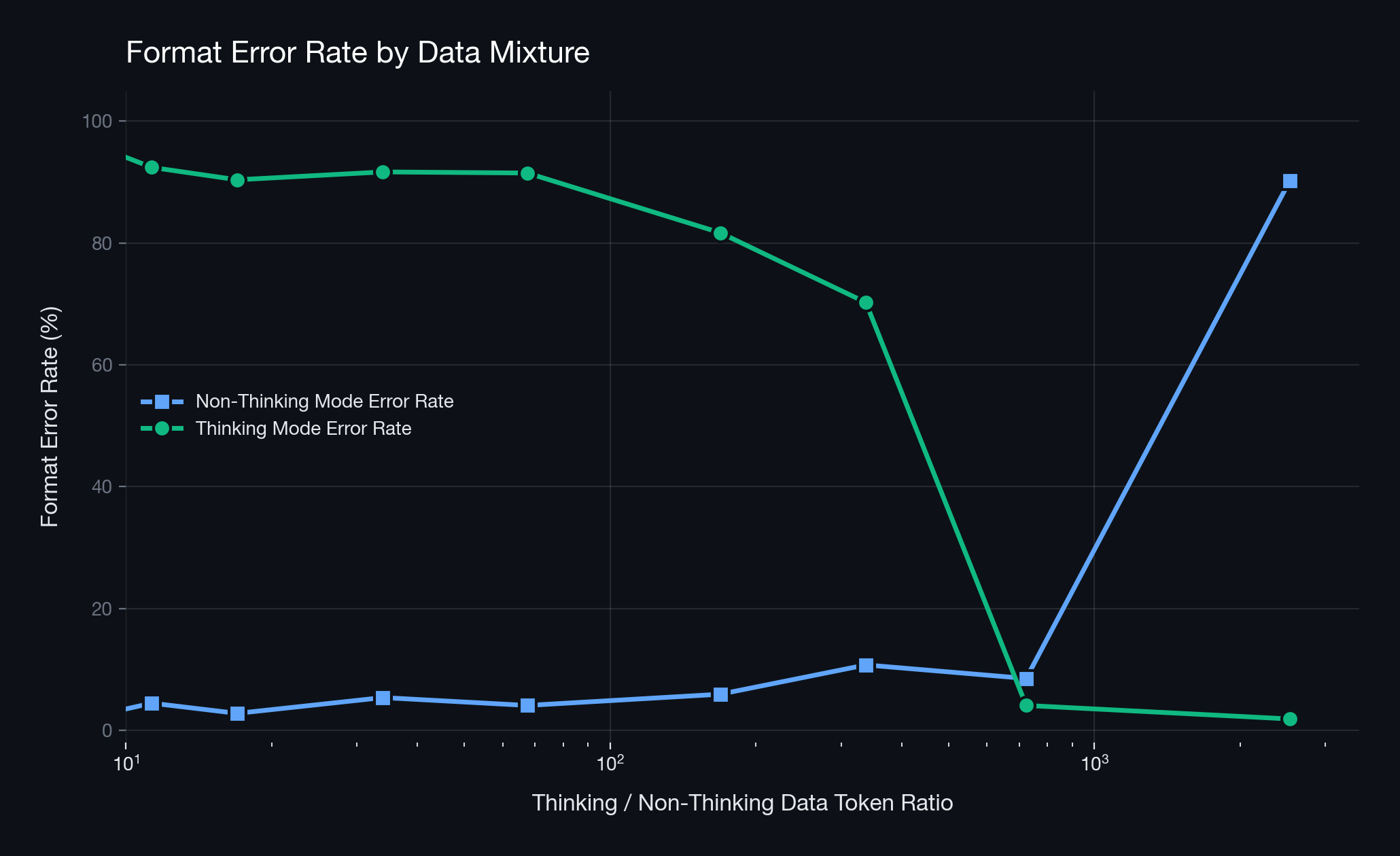
In practice, however, ratio adjustment alone was insufficient to resolve mode collapse. While an optimal point where format was maintained in both modes did exist, it was highly unstable and results would easily fluctuate with slight ratio changes. In particular, since the optimal ratio can vary depending on the data’s domain and length, the ratio adjustment approach requires extensive experimentation and is difficult to reproduce.
Approach 2: Sequential Training
The second approach is sequential training — first firmly training thinking mode, then training non-thinking mode to achieve coexistence. Looking at Qwen3’s post-training process, thinking capability is established first before integrating non-thinking mode, so we applied a similar pipeline directly.

When trained only on thinking data, thinking mode operated relatively stably as expected. However, when non-thinking data was subsequently trained, non-thinking mode worked normally while thinking mode completely collapsed with a 100% format error rate. In other words, in sequential training, the later-trained mode strongly overwrites the earlier-trained mode, and this recipe alone was insufficient to achieve coexistence of both modes.
Approach 3: Training with Paired Responses per Mode for the Same Question
The last approach we tried was providing paired thinking/non-thinking mode responses for the same question during training. This idea is similar to the recipe used in Llama-Nemotron’s post-training process. In Llama-Nemotron, mode-specific responses for the same question are explicitly tagged with system instructions like “detailed thinking on/off,” guiding the model to learn to determine the reasoning mode based on input signals. While Llama-Nemotron used a different model to generate mode-specific responses, we simply generated non-thinking responses by removing the intermediate reasoning wrapped in <think>...</think> from the thinking data.
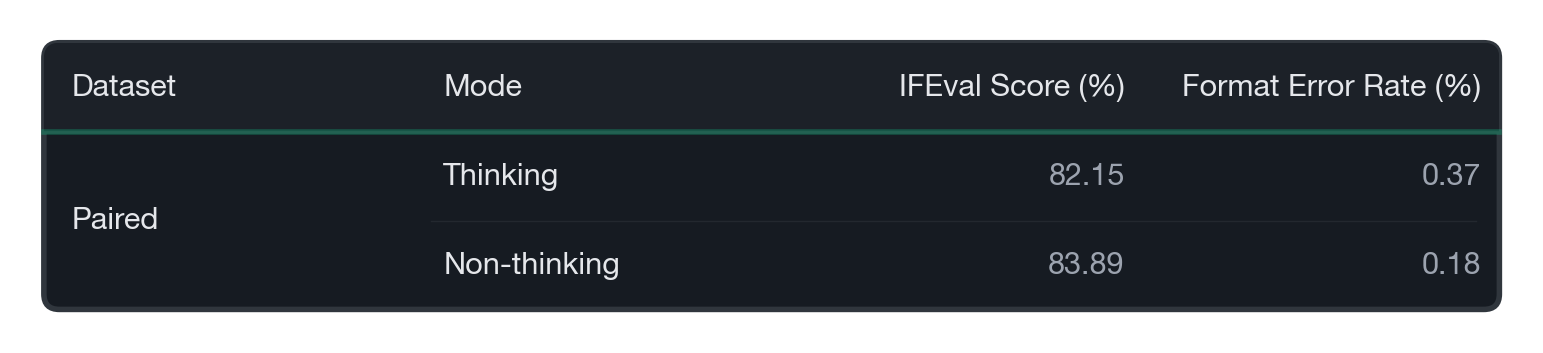
The results were markedly different with this data. Both modes showed high performance alongside low format error rates. In other words, when mode-specific responses were paired for the same question, the mode collapse pattern was significantly mitigated.
Why Paired Responses Worked: Making the Think Token a True Switch
The reason the last approach was most effective is simple. Since the same question is shared, the only cue the model can use to distinguish the reasoning mode is essentially the <think> or </think> token. As a result, the model has no room to infer the reasoning mode from biased hints like the question’s domain, difficulty, or tone, and instead learns the think token as a genuine branching signal. Conversely, in other approaches where “some questions exist only in thinking mode and others only in non-thinking mode,” the input distribution easily becomes entangled with the reasoning mode, which likely made mode collapse more prone to occur.
A Model-Based Alternative: Merging in Parameter Space
Through our data-based experiments, we concluded that using paired responses per mode is effective for resolving mode collapse. However, this approach has the drawback that training time increases with more data. Therefore, we explored whether the same goal could be achieved without training through a model-based approach rather than a data-centric one.
Model merging is a technique that interpolates the parameters of models specialized in different domains in parameter space to create a single model that maximally preserves performance across each domain. This idea has the advantage of not requiring training and has been used in various LLMs such as LongCat-Flash-Thinking and Command A.
Using the thinking and non-thinking data from earlier, we can obtain two models that each operate in only one reasoning mode. In this section, we share the experiment and results of merging these two models to create a single model without mode collapse.
Experimental setup summary
- Pre-trained Model: Qwen3-30B-A3B-Base
- Thinking Model: trained only on thinking data
- Non-thinking Model: trained only on non-thinking data
- Domain: instruction-following
- Evaluation
- IFEval score (↑): instruction-following performance metric
- Format error rate (↓): rate of violating the expected format (think tags, etc.) for the given mode
- e.g., for thinking mode, the proportion of samples that fail to produce the
<think>...</think>format
- e.g., for thinking mode, the proportion of samples that fail to produce the
- Dataset
- Thinking data 46k (for thinking mode)
- [request] +
<think>[intermediate reasoning]</think>[answer]
- [request] +
- Non-thinking data 37k (for non-thinking mode)
- [request] +
</think>[answer]
- [request] +
- Thinking data 46k (for thinking mode)
The Simplest Approach: Linear Merging
There are various model merging methods. Examples include the simplest and most intuitive linear merging, TIES-Merging which leverages task vector post-processing, and HC-SMoE which can utilize mixture-of-experts architecture. We explored all of these methods, but the simplest and most intuitive linear merging was the most effective in terms of maintaining performance and resolving mode collapse.
Linear merging creates a single model by linearly interpolating the parameters of multiple models. We used the thinking model and non-thinking model as the ingredients for merging. First, the IFEval benchmark performance of the thinking model and non-thinking model was 72.3 and 73.0 respectively, and the format error rates for each reasoning mode were 0.9% and 0%. We then observed how IFEval performance and format error rates changed with the mixing ratio.
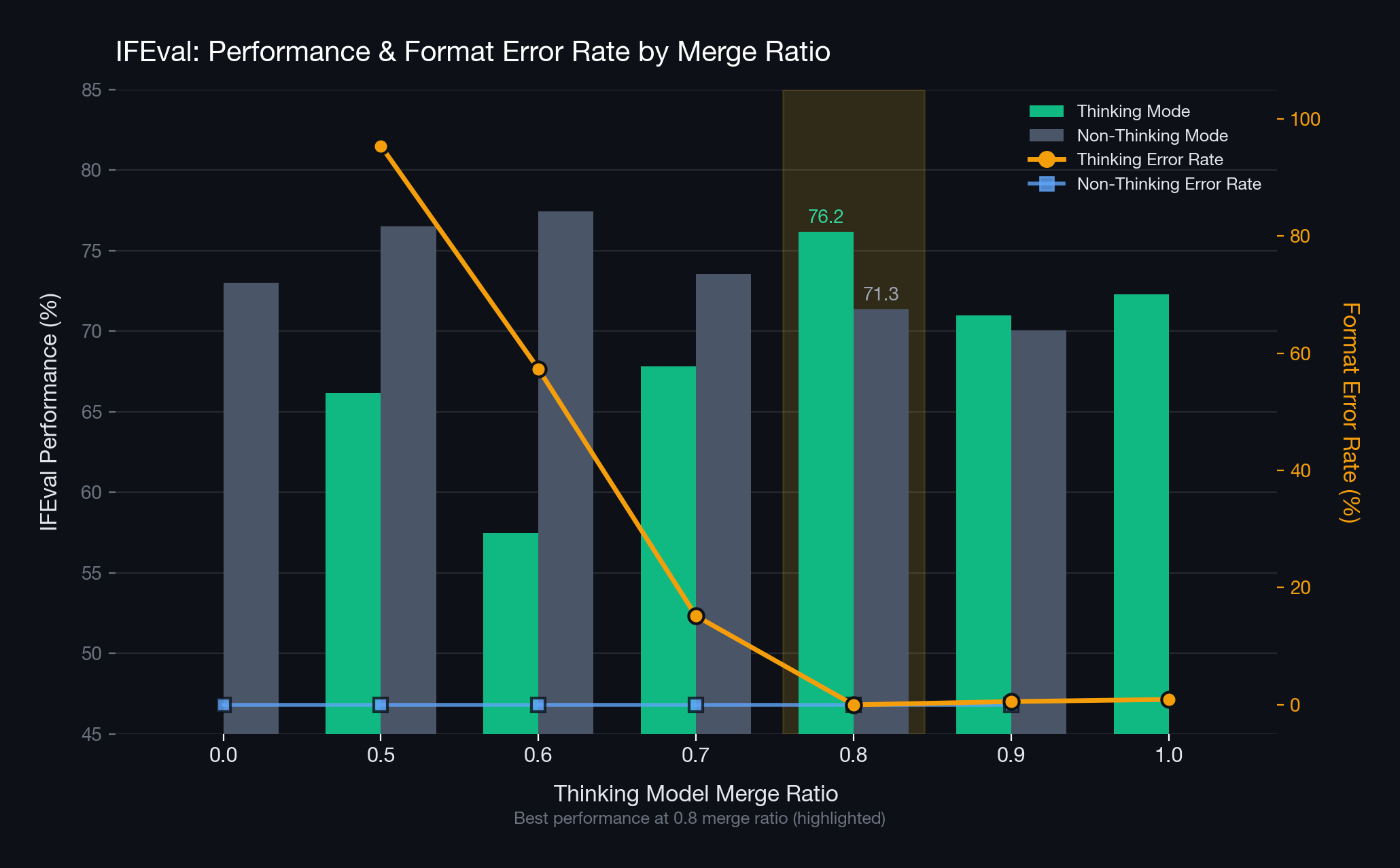
Let us first observe the graph from the perspective of format error. For non-thinking mode, format errors hardly occurred across all ratios. However, for thinking mode, format errors tended to increase as the non-thinking model’s proportion grew. Qualitative analysis revealed that in most cases, the model generated answers without intermediate reasoning, resulting in missing </think> tags. This shows that as the non-thinking model’s proportion increases, the merged model behaves more like the non-thinking model.
We selected the model with low format errors and good performance in both modes. The optimal ratio turned out to be 8:2 (thinking model to non-thinking model). At the 8:2 ratio, no format errors occurred in either mode — a lower rate than even the individual ingredient models. In terms of performance, thinking mode improved by 3.9 over the thinking model, while non-thinking mode decreased by 1.7 compared to the non-thinking model. This is a positive outcome that definitively controls mode collapse while well-preserving domain performance.
Validation Beyond the Training Domain: Out-of-Domain Evaluation
We conducted evaluations on the GPQA and AIME25 benchmarks — outside the training domain — to verify whether the model merged at the 8:2 ratio universally reduces format errors across diverse domains. The results showed that the merged model effectively reduced format errors not only in the training domain but also in other domains. Furthermore, domain performance at the 8:2 ratio was superior to the ingredient models.
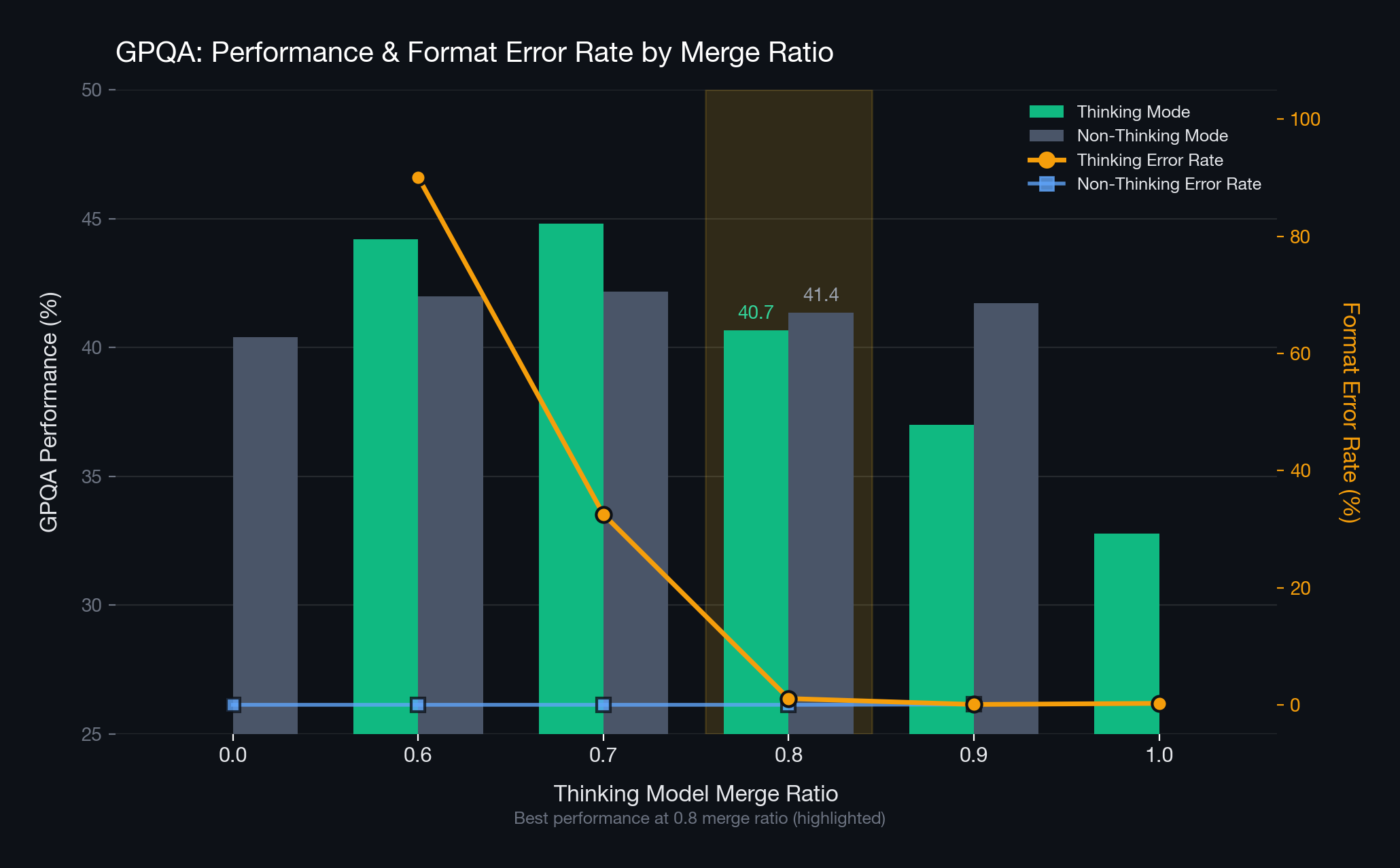
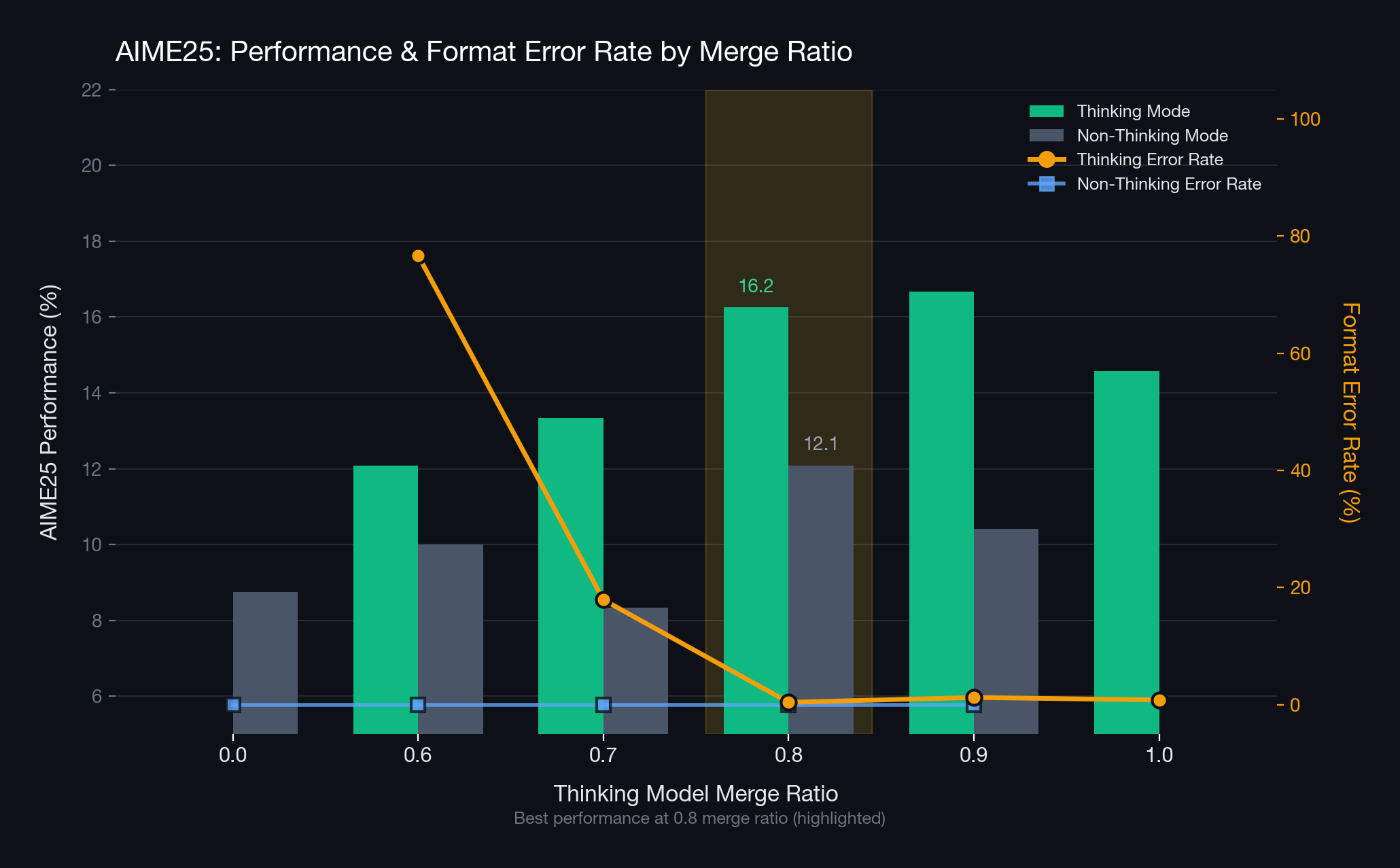
Conclusion
The need for reasoning mode selection is simple: for some requests, a “fast answer” is quality itself, while for others, a “deeply reasoned answer” is the right answer even if it takes time. To this end, we clearly distinguished reasoning modes using <think> and </think>. However, problems emerged during actual training. Even with signals in place, mode collapse — where the model operates in only one mode — occurred frequently. Through this process, we confirmed that not only the content of the answer but also strictly adhering to the format is a core aspect of reasoning mode selection technology.
After experimenting with various data recipes, the most effective method was training with paired thinking/non-thinking responses for the same question. This approach guides the model to determine the reasoning mode based solely on the think token, without relying on hints like the question’s tone or difficulty. We also considered cases where the training cost from paired responses is burdensome. For this, we trained models specialized in each reasoning mode and then conducted merging experiments via linear merging. At a specific ratio (e.g., 8:2), we confirmed that both modes can be stably controlled without additional training. The insights gained from this process were applied to the training recipe of the A.X K1 foundation model.